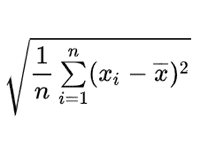テキストマイニング 【text mining】
概要
テキストマイニング(text mining)とは、定型化されていない文字情報(テキストデータ)の集まりを自然言語解析などの手法を用いて解析し、何らかの未知の有用な知見を見つけ出すこと。
解説 「データマイニング」(data mining)の手法を非定型のテキストデータに応用したもので、自然言語の文の蓄積として集められたデータを分析し、鉱山から鉱石などを掘り出す(mining)ように、業務や製品に役立つ情報を探し出す。
目的や具体的な技術は様々だが、多くの場合、文章に形態素解析を行ってテキストを単語やフレーズに分解し、特定の表現の出現頻度やその増減、複数の表現の関連性や時系列の変化などを調べる。
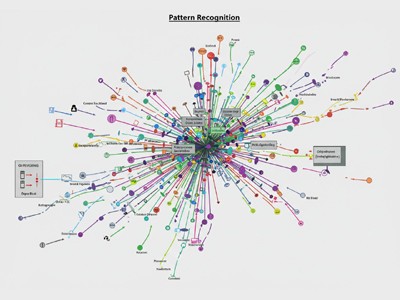
これにより、知られていなかった問題点を見出したり、様々な要素や要因の間の結びつきを可視化したり(共起ネットワーク分析)、顧客や消費者の評判(肯定的か否定的か)や時系列の推移を把握したりする(センチメント分析)ことができる。
対象となるデータの例として、アンケートや報告書などに含まれる自由記述の文章、電子掲示板(BBS)やSNSの書き込み、ニュース記事、OCRでスキャンしてテキストデータ化した過去の書籍、雑誌、新聞の記事などが挙げられる。
(2018.12.11更新)