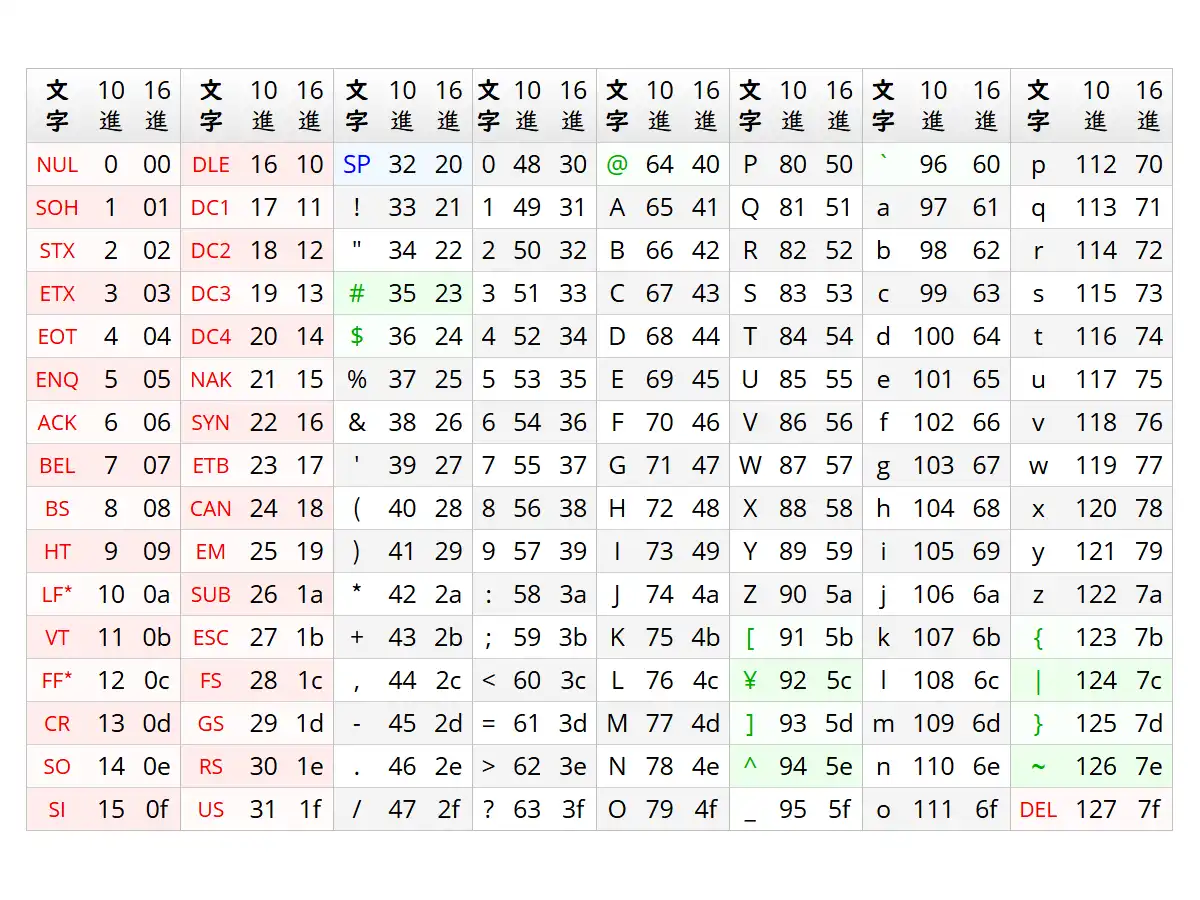
主に英語で必要な文字を収録したコード規格で、0番から127番までの番号(正確には2進数で0000000から1111111まで)について、各番号がどの文字を意味するかという対応関係を定めている。例えば英大文字の「A」はASCIIコードでは65番(16進数 で41、2進数で1000001)で表される。
収録されているのはA~Z、a~zのラテンアルファベット(ローマ字)、0~9のアラビア数字、約物(引用符 や括弧 、疑問符 、感嘆符 、カンマ 、ピリオド など)、記号(数学記号やドルマーク 、アットマーク など)、空白文字、制御文字 (改行文字 やタブ文字 、古い通信制御文字など)などである。
1963年にASA(アメリカ規格協会 、現在のANSI )が定めた規格で、コンピュータ 上の文字コード の有力な標準として世界的に広く普及した。現在でも英文の文字情報の記述やコンピュータ 言語の表記などに用いられている。一般的なキーボード にはASCII文字 に対応するキーが配されている。
ISO/IEC 646
国際標準化機構 (ISO )は1967年にASCIIを元に一部を国際化 したISO 646を標準化 した。大半の文字はASCIIと共通だが、35番(ASCIIでは#)、36番($)、91([)~94番(^)、123({)~126番(~)は各国の事情次第で別の文字を割り当てても良いことになった。
欧州では「$」の部分に自国通貨の記号を割り当てたり、置き換え可能な領域を用いてダイアクリティカルマーク 付きのアルファベットを収録した拡張規格が利用された。1991年にISO 646規格は所管がIEC との合同委員会JTC1に移ったため、以降は「ISO/IEC 646」が正式な表記である。
文
10
16
NUL 0 00 SOH 1 01 STX 2 02 ETX 3 03 EOT 4 04 ENQ 5 05 ACK 6 06 BEL 7 07 BS 8 08 HT 9 09 LF* 10 0a VT 11 0b FF* 12 0c CR 13 0d SO 14 0e SI 15 0f
文
10
16
DLE 16 10 DC1 17 11 DC2 18 12 DC3 19 13 DC4 20 14 NAK 21 15 SYN 22 16 ETB 23 17 CAN 24 18 EM 25 19 SUB 26 1a ESC 27 1b FS 28 1c GS 29 1d RS 30 1e US 31 1f
文
10
16
SP 32 20 ! 33 21 " 34 22 # 35 23 $ 36 24 % 37 25 & 38 26 ' 39 27 ( 40 28 ) 41 29 * 42 2a + 43 2b , 44 2c - 45 2d . 46 2e / 47 2f
文
10
16
0 48 30 1 49 31 2 50 32 3 51 33 4 52 34 5 53 35 6 54 36 7 55 37 8 56 38 9 57 39 : 58 3a ; 59 3b < 60 3c = 61 3d > 62 3e ? 63 3f
文
10
16
@ 64 40 A 65 41 B 66 42 C 67 43 D 68 44 E 69 45 F 70 46 G 71 47 H 72 48 I 73 49 J 74 4a K 75 4b L 76 4c M 77 4d N 78 4e O 79 4f
文
10
16
P 80 50 Q 81 51 R 82 52 S 83 53 T 84 54 U 85 55 V 86 56 W 87 57 X 88 58 Y 89 59 Z 90 5a [ 91 5b ¥ 92 5c ] 93 5d ^ 94 5e _ 95 5f
文
10
16
` 96 60 a 97 61 b 98 62 c 99 63 d 100 64 e 101 65 f 102 66 g 103 67 h 104 68 i 105 69 j 106 6a k 107 6b l 108 6c m 109 6d n 110 6e o 111 6f
文
10
16
p 112 70 q 113 71 r 114 72 s 115 73 t 116 74 u 117 75 v 118 76 w 119 77 x 120 78 y 121 79 z 122 7a { 123 7b | 124 7c } 125 7d ~ 126 7e DEL 127 7f
*
LF はNL、FFはNPと呼ばれることもある。
*
赤字 は
制御文字 、
SP は空白文字(スペース)、黒字と
緑字 は図形文字。
*
緑字 はISO 646で文字の変更が認められ、日本では
バックスラッシュ が
円記号 になっている。
8ビット目を利用した拡張規格
ASCIIでは1文字を7ビット で表すが、現代のコンピュータ のほとんどはデータ の基本的な管理単位が1バイト (8ビット )であるため、実際には1文字を8ビット で表している。
残りの1ビット はもともとデータ 伝送時の誤り検出符号(パリティビット )などとして用いられてきたが、電子回路や通信システムの信頼性向上などを受け、この1ビット を活用してASCIIを拡張する試みが行われるようになった。
ASCIIを拡張したコード体系では、0番から127番まではASCIIと同じで、ASCIIに規定の無い128番~255番の領域に独自の文字を割り当てている。例えば、日本国内で用いられたJIS X 0201では、この領域にカタカナ(いわゆる半角カナ )や句読点(。、)、鉤括弧 (「」)を配置して限定的ながら日本語を使えるようにしている。
後にASCII拡張についても標準化 の動きが起こり、8ビットコードや複数バイトコード の扱い、各国の拡張コードの切り替え方式などを定めたISO/IEC 2022 や、これに基づいて具体的な8ビット の文字コード を規定したISO/IEC 8859 などの規格が策定された。追加の文字を含めても1バイト で十分なヨーロッパ各国の言語などではISO/IEC 8859 が標準的な文字コード として普及している。