読み方 : きょうしデータ
教師データ 【training data】 トレーニングデータ / 訓練データ / 教師信号
概要
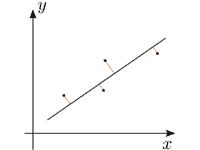
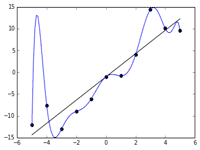
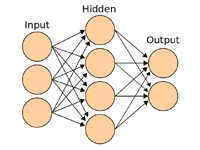
教師データ(training data)とは、機械学習で学習に用いるデータセットのうち、「例題」と「正解」を対応付けた形式に整理されたデータ。このようなデータを用いる学習方式を「教師あり学習」という。
解説 対象分野の知識について、例題と正解がペアになっている形式の学習データである。例題のデータを入力すると、正解のデータが出力されるようにモデルを訓練していく。学習が完了すると、例題と同じカテゴリーの未知のデータに対して、正解と思われるデータを導き出して出力する。
例えば、数字を手書きした画像(例題)と、そこに写っている数字(正解)をペアにした教師データをたくさん用意し、画像を入力すると数字を答えるモデルを作成すると、手書きの数字を認識するシステムを作ることができる。
機械学習システムに分類を行わせたい場合は、正解がラベルや離散値など限定された教師データを用意する。予測や推論などの回帰を行わせたい場合は、正解が任意の文字列や実数など、任意の内容を取り得る教師データを用いる。
人間がコンピュータで管理しているデータがそのまま教師データになるとは限らず、「例題と正解のペア」という形式に整理しなければならないため、用途や分野によっては教師データの準備に馬鹿にならない手間やコストがかかってしまうこともある。
文字データや画像データなど例題となり得る何らかのデータ集合に対して、人間が正解となるデータを付与していく作業を「アノテーション」(annotation)という。画像分類など典型的な課題については無償で利用できる大規模な教師データのセットが公開されている場合もある。
問題の種類によっては元になるデータから自動的に教師データを作成できる場合がある。例えば、文章の穴埋め問題を解くシステムを作る場合、元になる文章の例がたくさんあれば、任意の位置の単語を抜き取った例題を作成し、抜き取った単語を正解とすればよい。これは大規模言語モデル(LLM)の学習などで用いられる手法の一つである。
(2024.3.13更新)