読み方 : ケーミーンズほう
k-means法【k-means clustering】k平均法
概要
k-means法とは、データ群を決められた個数の同類のグループに分類する手法の一つで、最初はランダムにグループを割り当て、各グループの重心の計算と、最も重心が近いグループへの移籍を繰り返すことで徐々に近いもの同士を集めていく方式。
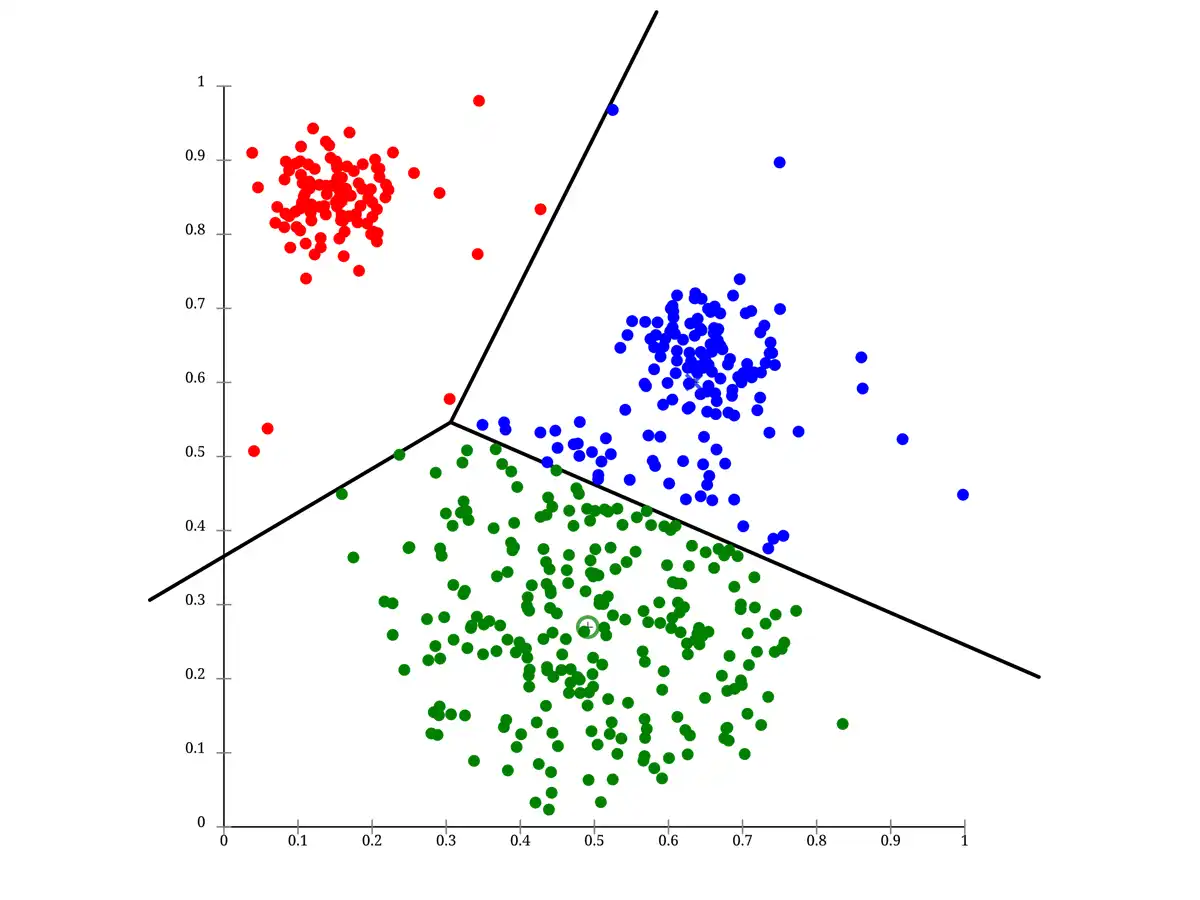
与えられたデータ群を近いもの同士のグループに自動的に分類するデータ解析手法を「クラスタリング」という。似た者同士のグループを「クラスタ」という。分類の基準は与えずに、値の分布から近いものを集めるため、機械学習の手法としては「教師なし学習」に分類される。
k-means法は、あらかじめ与えられたk個のクラスタにデータを分類する手法である。最初にすべてのデータをランダムにいずれかのクラスタに所属させる。各クラスタに所属するデータ群の各変数の平均値を取ると、その時点のクラスタの重心(中心と呼ぶこともある)を求めることができる。
すべてのデータについて、各クラスタの重心との距離を求め、自らと最も重心が近いクラスタへ移籍する。その後、再び各クラスタの重心を求め、各データは最も重心が近いクラスタへ移籍する。この重心の算出と移籍を繰り返すと、次第に近いデータ同士のクラスタが形成される。移籍するデータの数が規定の値を下回るなど、何らかの基準を設けて繰り返しを打ち切る。
重心の算出には通常は算術平均を用いるが、データの特性に応じて他の方法を用いてもよい。いくつのクラスタに分類するか(kの値)は事前に人間が決める必要があり、適切なクラスタ数を自動的に決める仕組みは提供されない。最初のランダムな割り当て(の偏り方)によって最終的な結果も影響を受けることが知られており、安定性を高めるため、k-means法自体を何度も繰り返して結果を平均するといった手法が用いられることがある。
(2025.10.1更新)
